某个项目上反馈投标文件导入异常慢,经过排查,发现慢在解压缩上。进一步排查发现,使用unzip命令解压缩并不慢,60MB的文件5秒就能解压缩完成,而通过Java代码解压缩需要5分钟。
通过以上信息,可以给出一个初步的结论:解压缩慢的问题和服务器本身关系不大(包括CPU、IO),大概率还是Java代码层面的问题。
既然定位是代码问题,那就将解压缩代码剥离出来,做成一个最小可复现测试用例,精简的代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
|
public static String unZip(String zipPath, String unZipPath) {
try (ZipArchiveInputStream zis = new ZipArchiveInputStream(new FileInputStream(zipPath), "GBK")) {
ZipArchiveEntry entry;
while ((entry = zis.getNextZipEntry()) != null) {
long start = System.currentTimeMillis();
if (entry.isDirectory()) {
String dirName = entry.getName();
dirName = dirName.substring(dirName.lastIndexOf(File.separator) + 1);
new File(unZipPath + File.separator + dirName).mkdirs();
}
else {
String entryName = entry.getName();
entryName = entryName.replace("\\", File.separator);
File f = new File(unZipPath + File.separator + entryName);
if (f.exists()) {
new File(unZipPath + File.separator + entryName).delete();
}
if (!new File(f.getParent()).exists()) {
new File(f.getParent()).mkdirs();
}
new File(unZipPath + File.separator).mkdirs();
FileOutputStream os = new FileOutputStream(unZipPath + File.separator + entryName);
int n = 0;
byte[] content = new byte[1024 * 1024];
long cost = 0;
while (-1 != (n = zis.read(content))) {
System.out.println(n + "==4==" + entry.getName());
long start2 = System.currentTimeMillis();
os.write(content, 0, n);
cost += (System.currentTimeMillis() - start2);
}
System.out.println(cost + "==3==" + entry.getName());
os.close();
}
System.out.println((System.currentTimeMillis() - start) + "==1==" + entry.getName());
}
return unZipPath;
}
catch (Exception e) {
e.printStackTrace();
}
return "";
}
|
通过日志定位,耗时长的是在写文件内容上。一般优化写入速度的手段无非是扩大写缓冲区,减少写操作的系统调用次数。因此,首先尝试的是增加缓冲区的大小(L25,增加content字节数组长度)。但是验证下来没有效果。
此时,排查陷入了停滞,没有了明确的排查方向。在此期间,我又做了两件事:
- 测试磁盘性能
问题出现在文件写入上,还是得再确认一下文件的写入性能,使用dd命令测试。
1
2
|
time dd if=/dev/zero of=./test.dba bs=4k count=10000
time dd if=/dev/zero of=./test.dba bs=4M count=10
|
其中第一条命令执行需要4分钟,第二条命令执行只需要3秒。从测试结果看,增加写缓冲区大小确实可以提升写入速度。但是Java代码为什么没效果呢?
- 继续添加日志分析
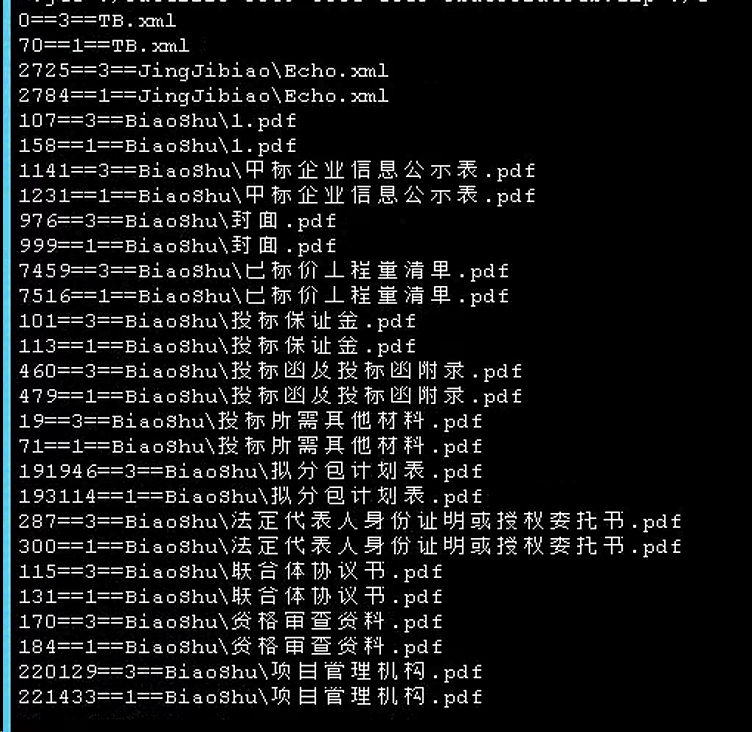
尝试在27行while循环内增加日志,打印每次写入的耗时,分析日志后发现了问题。按照缓冲区10MB计算,压缩包中最大的一个文件为35MB,那照理这份文件只会打印4次日志,但实际打印日志次数远远多余4次。进一步,将while循环内的日志修改为上面代码中的第28行,打印每次读取的字节数,发现虽然缓冲区设置很大,但实际每次读取的字节数只有500多。
至此,问题原因终于查明:由于解压缩的ZipArchiveInputStream(ZipInputStream同样如此)每次读取的字节数有限(500左右),相当于以小缓冲区频繁地写文件,导致写性能下降。
查明了问题原因,解决方案就很简单,将原来的FileOutputStream(L23)用BufferedOutputStream包装一下:
1
|
BufferedOutputStream os = new BufferedOutputStream(os1, 4*1024*1024);
|
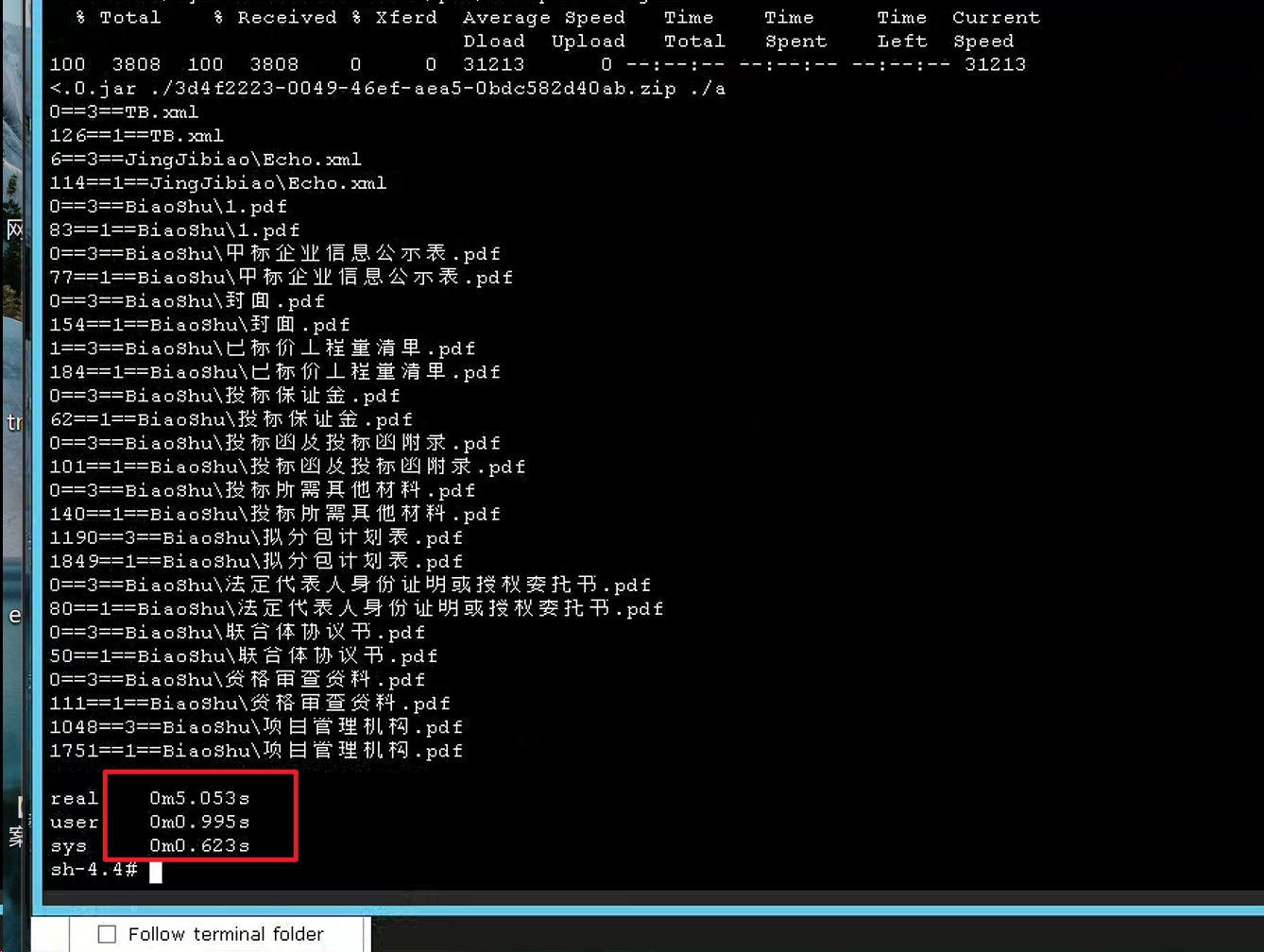
修改后,60MB文件解压缩解压缩从原来的5分钟,缩短到了5秒。
回顾这次问题排查过程,其中最大的盲点或误区是:认为给定长度的缓冲区,InputStream就会尽量把缓冲区填满后再返回。
评论